
موتور دیتابیس چیست؟ تعریف بخش های Database Engine

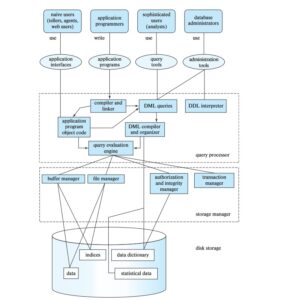
یک موتور پایگاه داده (Database Engine) هسته اصلی هر سیستم مدیریت پایگاه داده (DBMS) است که مسئولیت مدیریت، ذخیرهسازی، بازیابی و امنیت دادهها را بر عهده دارد. اگرچه پیادهسازیهای مختلف (مانند MySQL، PostgreSQL، Oracle) جزئیات متفاوتی دارند، در فلسک دولوپر توضیح میدهیم دیتابیس انجین چیست؟ و از چه قسمت هایی تشکیل شده است.
یک موتور پایگاه داده رابطهای (RDBMS) استاندارد معمولاً از ماژولها و بخشهای اصلی زیر تشکیل شده است:
- Parser که وظیفه تحلیل پردازش دستورات را دارد.
- Query Optimizer که وظیفه اجرای بهینه را دارد. معمولا موتورهای دیتابیس یک Execution Plan دارند که تصمیم میگیرد با چه ترتیبی join ها را انجام دهد یا از کدام ایندکس ها استفاده کند.
- Transaction Manager موظف به رعایت اصول ACID است و بخصوص کنترل همزمانی را بر عهده میگید. مثلا دو تراکنش وجود دارند در یکی گفته شده موجودی کیف پول 2 دلار شود و در دیگری گفته شده3دلار شود. این دو تراکنش نباید همزمان اجرا شوند بلکه باید یکی اجرا شده و حین اجرا جدول قفل شود سپس بعدی اجرا شود.
- Storage Manager تصمیم میگیرد چطور ذخیره در دیسک انجام شود مثلا بلوک های 8 بایتی یا 16 بایتی ذخیره شود، برخی داده ها را از دیسک خوانده به رم منتقل میکند و عکس آنرا انجام میدهد.
- مدیریت حافظه: مدیریت کش و اینکه چه مواردی در رم نگهداری شوند و چه موارد حذف یا جایگزین شوند.
- WAL Write Ahead Log : این ماژول مسئول حفظ پایداری دادهها در صورت بروز خطاهای سختافزاری، قطع برق یا کرش کردن سیستم است. در واقع همواره باید لاگ تراکنشها ذخیره و در صورت نیاز ریکاوری شوند.
- Access Control : کنترل دسترسی و احراز هویت.
بطور کلی میتواند گفت جریان کاری دیتابیس از ارسال کوئری توسط کاربر شروع میشود، ماژول Parser آنرا بررسی و تحلیل میکند و به Optimizer تحویل میدهد. Optimizer تصمیم میگیرد چطور آنرا اجرا کند، و Buffer Manager دادههای مورد نیاز را از دیسک به RAM میآورند و اگر موردی در رم اضافی است آنرا حذف میکنند تا از خطا و سرریز شدن حافظه جلوگیری شود. Transaction Manager اطمینان حاصل میکند که عملیات به صورت اتمی و ایمن انجام میشود. Recovery Manager تغییرات را در لاگ ثبت میکند و نهایتا آنچه خواسته شده به کاربر تحویل میشود.
بطور کلی باید بدانیم که دستورات ما به سمت دیتابیسها دو دسته هستند:
- DML که مخفف Data Manipulation Language است و رسالت آن اعمال تغییر در داده هاست. البته بطور کلی دستوراتی که مستقیما با داده ها سروکار دارند از جمله Delete, update, Select, Insert همگی جزو DML هستند.
- DDL مخفف Data Definition Language است که با ساختارها سروکار دارد مثل Create یا Alter درواقع دستور ایجاد دیتابیس یا جدول همگی DDL هستند.
در این میان دستوراتی وجود دارند بنام سنجاق یا Constraints که در کنار سایر دستورات قرار میگیرد مثل Primary Key یا NotNull که در کنار دستورات DDL قرار میگیرند.
مدیریت تراکنش در دیتابیس دقیقا چطور انجام میشود؟
مدیر تراکنش (Transaction Manager) در موتور پایگاه داده، مغز متفکر تضمینکننده یکپارچگی و پایداری دادههاست که با پیادهسازی اصول ACID (اتمی بودن، سازگاری، پایداری، جداسازی) کار میکند. وقتی یک تراکنش آغاز میشود، این ماژول یک «محوطه ایزوله» ایجاد میکند و تمام تغییرات موقت را در یک حافظه میانی (مانند Undo Logs یا نسخههای قبلی داده) نگه میدارد. اگر در حین انجام عملیات خطایی رخ دهد یا کاربر دستور لغو (Rollback) را صادر کند، مدیر تراکنش با استفاده از این اطلاعات پشتیبان، تمام تغییرات انجامشده را به حالت قبل از شروع تراکنش بازمیگرداند، گویی که هیچ اتفاقی نیفتاده است. از سوی دیگر، اگر تمام مراحل با موفقیت طی شوند، با صدور دستور Commit، این تغییرات نهایی شده و برای سایر تراکنشها قابل مشاهده میشوند. این فرآیند تضمین میکند که پایگاه داده هرگز در یک وضعیت نیمهکاره یا ناسازگار قرار نگیرد، حتی اگر سیستم ناگهان خاموش شود.
بخش دوم وظیفه حیاتی مدیر تراکنش، مدیریت همزمانی (Concurrency) و جلوگیری از تداخل بین کاربران متعدد است که به دادههای یکسان دسترسی دارند. برای این کار، از مکانیسمهای قفلگذاری (Locking) یا مدیریت نسخهسازی (MVCC) استفاده میشود تا مطمئن شود خواندن دادهها توسط یک کاربر، مانع نوشتن توسط کاربر دیگر نمیشود و برعکس. در این مرحله، مدیر تراکنش تعیین میکند که کدام تراکنشها باید منتظر بمانند (Wait) و کدامها میتوانند همزمان اجرا شوند، تا از مشکلاتی مانند «خواندن کثیف» (Dirty Read) یا «از دست رفتن بهروزرسانی» جلوگیری شود. در نهایت، با نظارت بر ترتیب اجرای دستورات و اطمینان از اینکه هر تراکنش به صورت اتمی (یا همهچیز یا هیچچیز) پردازش میشود، این ماژول تعادل ظریفی بین سرعت عملکرد و امنیت دادهها برقرار میکند.
تفاوت بین MariaDB و PostgreSQL در مدیریت تراکنش ها
تفاوت اصلی در مکانیسم مدیریت همزمانی و پایداری است. PostgreSQL از مدل پیشرفتهای به نام MVCC (Multi-Version Concurrency Control) استفاده میکند که به جای قفلگذاری طولانیمدت، برای هر تراکنش یک «تصویر» از دادهها در لحظه شروع آن ایجاد میکند؛ این باعث میشود خواندنها و نوشتنها بسیار سریعتر و بدون قفل شدن متقابل انجام شوند و نیاز به مدیریت پیچیده قفلها کمتر باشد. در مقابل، MariaDB (بهویژه در موتور پیشفرض آن یعنی InnoDB) ترکیبی از قفلهای سطح ردیف (Row-Level Locking) و MVCC را به کار میبرد، اما رویکرد آن بیشتر بر مدیریت صریح قفلها برای تضمین سازگاری فوری متمرکز است، اگرچه InnoDB نیز از MVCC برای خواندنهای غیرهمگام پشتیبانی میکند. همچنین، PostgreSQL در مدیریت لاگهای WAL (Write-Ahead Logging) برای بازیابی پس از کرش، ساختار منسجمتر و مستندتری دارد، در حالی که MariaDB/MySQL ممکن است در سناریوهای نوشتن بسیار سنگین همزمان، نیاز به تنظیمات دقیقتری برای جلوگیری از گلوگاههای قفلگذاری داشته باشد.





